Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning
논문 링크 - Playing Atari with Deep Reinforcement Learning
위 논문은 Deepmind가 2013년도에 NIPS workshop에서 발표한 논문이다.
RL을 적용할때 많은 사람들이 high dimensional sensory input을 직접 사용하고 싶었지만 이때까지 너무 방대한 양이라서 직접 사용하는건 불가했고 이는 결국 확장성의 문제까지 왔기 때문에 사실상 침체기였다.
그런데 이 시기에 deep learning 논문이 나왔고 이를 RL을 적용해보기위해 사용해봤지만 실제로 RL에서는 크게 2가지의 이유로 사용할 수 없었다.
- test 데이터의 labeling이 되어있지 않는다.
- DL의 data sample들은 서로 independent해야하지만 RL은 correlated state들의 sequences들로 이루어져있다.
그래서 실제로 DL을 적용해본 팀이 있기는 하지만 성공하지 못했다. 그런데 deepmind에서는 각각의 이유에 대한 해결방안을 고려해서 이를 가능하게 했다.
- CNN을 수정된 Q-learning 활용해서 해결
- Experience replay를 활용해서 해결
notation
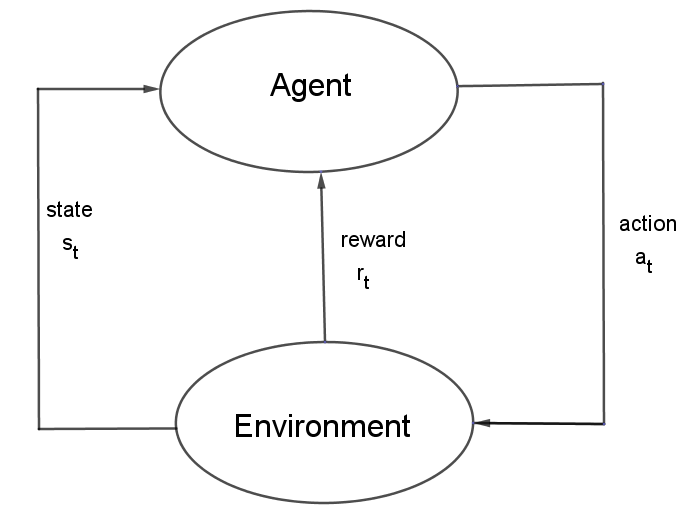
참고로 t시점의 action에 대한 reward와 state는 t+1시점
value function과 q-value function의 차이
value function 어떤 상태 \(s_t\)에서 나는 기대되는 보상이 얼마나 되는지?
Q-value function 어떤 상태 \(s_t\)에서 어떤 행동 \(a_t\)를 취했을 때, 얼마나 좋은 보상이 기대되는지?
optimal q-value function
q-value 중에서 가장 최적의 q-value 값을 갖는 q-value function을 의미 \(Q^{*}(s,a)=\max_{\pi }Q^{\pi}(s,a)=Q^{\pi^{*}}(s,a)\)
optimal q-value라는 것은 각각의 상태 s에 대해 행동 action을 정해서 최적의 보상 reward들의 합이다.
그렇게해서 나오는 것이 바로 bellman equation이다. \(\mathbf{E}_{s'}[r+\gamma\max_{a'}Q^{*}(s',a')\)ㅣ\(s,a]\)
기존의 q-learning은 table의 형태로 모든 state와 action을 표현했지만 이것은 확장성이 떨어져서 사용이 불가능하기 때문에 q-network를 사용해서 한다. 우리가 가지고 있는 q-network의 결과가 \(Q^{*}\)로 수렴하는 것이 목적이다. (w는 q-network의 weight)
\[Q(s,a,w)\approx Q^{*}(s,a)\]bellman equation에서 표현한 q-value를 \(y\), \(Q(s,a,w)\)를 \(y_{predict}\)라고 하면 q-network는 MSE lose를 이용한다.
\[l = (r + \gamma\max_{a}Q^{*}(s',a',w))^2\]table방식의 RL에서는 이 방법이 무한히 반복하면 수렴한다는 사실이 있지만 Q-network에서는 correlation의 문제로 잘 되지 않았다. 그래서 사용한 방법이 바로 experience replay라는 방법이다.
experience replay는 인접한 학습 데이터들이 sequence하게 들어오기 때문에 그 비효율성을 해결하기 위한 방법이다. 게임을 진행하는 agent는 데이터 (s,a,r,s’)를 replay memory에 저장한 다음, update할 때 replay memory에서 random하게 minibatch 크기의 sample을 뽑아서 계산한다.
이 방법을 사용하면 correlation을 해결해줄뿐만 아니라 학습에 크게 영향을 주는 경험 데이터를 여러번 사용할 수 있게되어 학습에 크게 도움이 된다.
그리고 deepmind가 nature에 논문을 제출할 때 Target network를 추가로 논문에 추가해서 올렸는데 target network는 dqn과 똑같은 neural network를 하나 더 만들어서 weight 값이 가끔씩만 update되도록 하는 방법이다. 이는 target(dqn에서는 bellman equation)이 Q(s,a,w)를 학습하는 순간에 같이 변화하기 때문에 학습 성능이 떨어져서 이 문제를 개선하기 위해서 생각한 아이디어이다.
예를 들어서 말 위에 탄 사람이 말을 움직이게 하기 위해서 말의 앞에 당근을 보여주면 말이 그 당근을 먹기위해 몸을 앞으로 움직인다. 하지만 실제로 말을 탄 사람은 말이 움직이기 때문에 당근이 양 옆으로 흔들리고 그래서 말을 실제로 앞으로 이동하는 것이 아니라 이리저리 움직인다. 그래서 우리는 당근이 말이 움직인다고해서 똑같이 흔들리는 것이 아니라 고정된 상태를 유지해야 한다.
그래서 target network의 weight 값을 DQN의 값으로 복사해 오지만 그 주기는 DQN보다는 천천히 한다. 그렇게해서 loss function을 계산할 때는 target은 target network의 weight을 사용해서 계산한다.
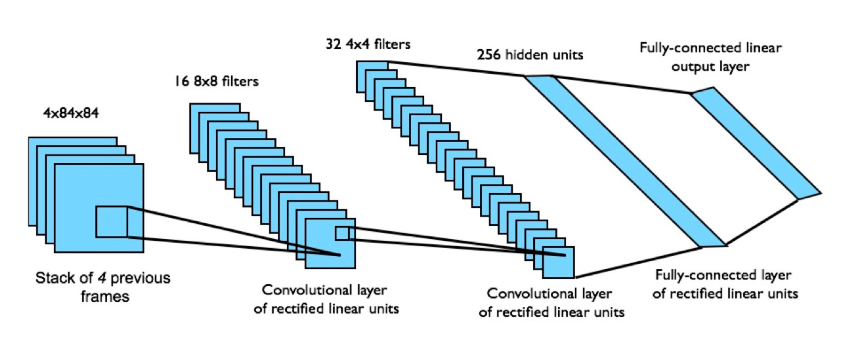
그래서 이 논문에서 적용한 NN은 3개의 convolutional layer와 2개의 fully-connected layer가 있는 구조인데 input으로 한장의 state 사진이 아니라 84x84 크기의 4장의 state를 받는다. 그리고 이 4장의 state에 똑같은 action으로 학습이 된다.

지금까지 설명한 논문의 알고리즘이다.
결과
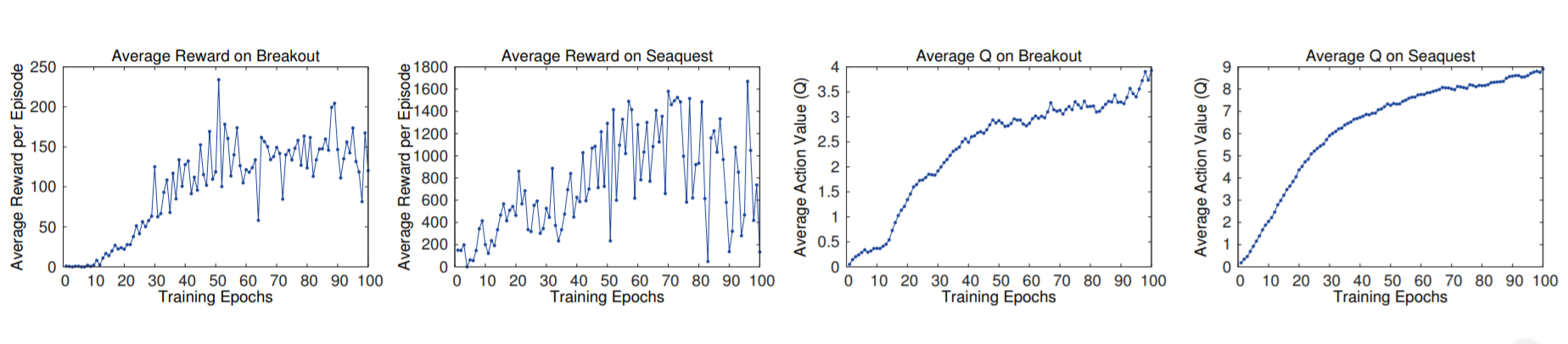
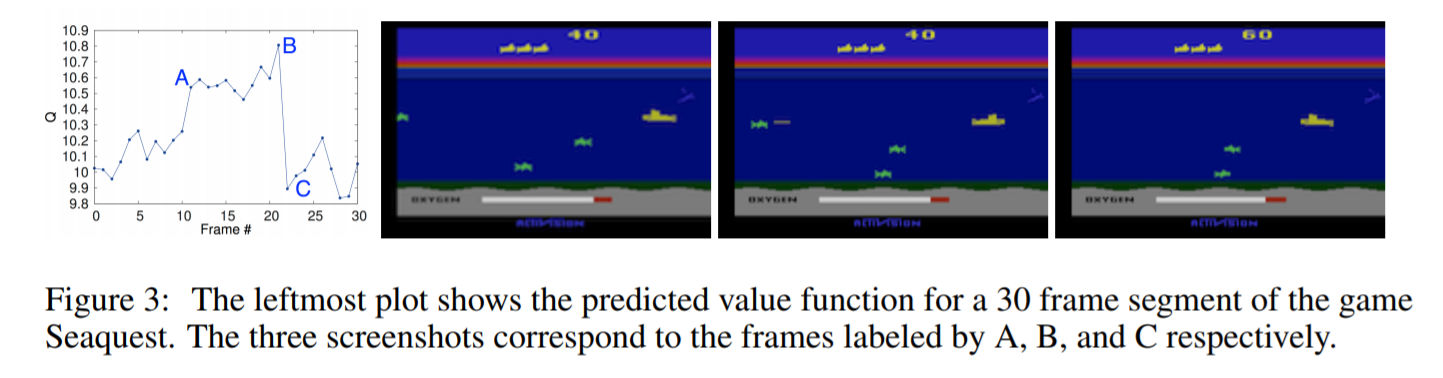
사실 결론에서 Q가 실제로 수렴하는 것에 대한 증명은 하지 못했다. 하지만 실제로 게임에 돌려서 실행했을 때 Q function이 잘 수렴하는지를 그래프를 통해서 밝힌다.
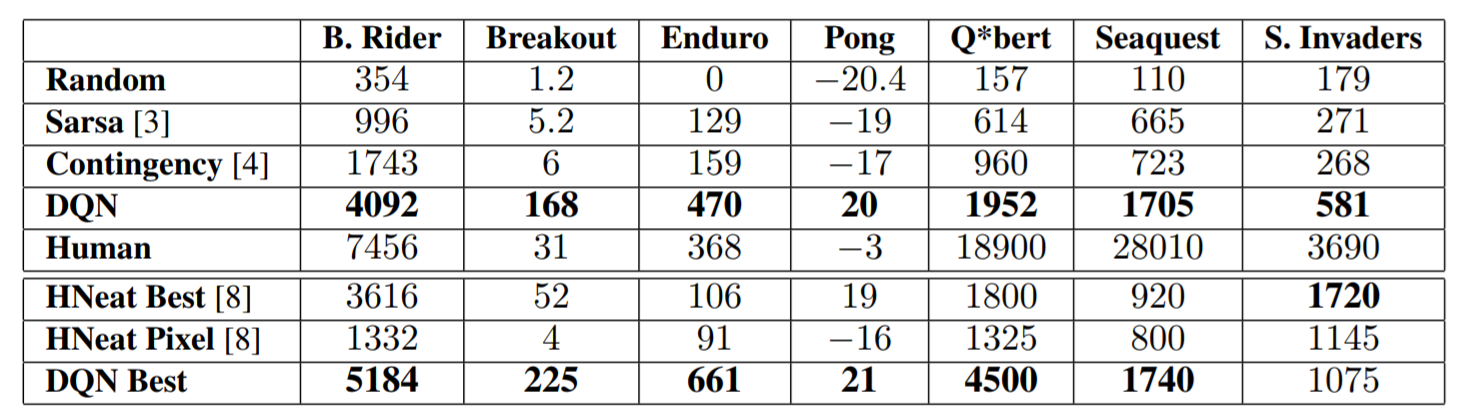
그리고 모든 부분에서 좋은 결과가 나온 것은 아니지만 사람이 실제로 플레이하는 것보다 잘한 게임도 있었고 만족스러운 performance를 보였다고 한다.
그리고 실제로 학습된 게임들의 predicted value function을 매 프레임마다 확인했을 때 실제 상태에 부합되는 값을 부여받았다고 보여주면서 잘 학습된 것을 보여줬다.
후속 논문
이 논문 이후로 dqn은 max를 사용하기 때문에 Q-value를 실제보다 높게 평가하는 경향(overestimate)가 있기 때문에 학습이 늦어진다고 한다. 그래서 이를 개선하기 위해서 Double DQN, dueling network 등이 나왔다.
replay memory 부분에서도 uniform random sampling하는 방식이 중요한 경험과 중요하지 않은 경험에 대해서 똑같은 가중치를 두기 때문에 중요한 경험에 더 큰 가중치를 두는 prioritized experience replay라는 기법도 후 속 논문으로 나왔다.